
By punctuation we mean the marking of the melodic
structure by inserting commas at boundaries that divide small
structural units. These commas are often signalled by micropauses.
Two models that automatically tries to find the positions of these
commas are presented. The first is based on a set of subrules;
some subrules mark a possible comma position while other subrules
remove these marks according to different conditions. The second
model is a neural network. They both use a small context of maximally
5 notes. The models are evaluated by using a set of 52 musical
excerpts and by comparing the results with the preferred punctuation
of a performer.
The marking of the structure is an important aspect of musical performance (e.g. Repp, 1992). The characteristic accelerando-ritardando shape that is commonly used to mark the phrase structure in romantic classical music has been modelled previously by Todd (1985, 1992) and Friberg (1995a). Another possibility to mark a structural boundary is to insert a comma, that is to introduce a micro pause at the boundary. With musical punctuation we mean here the insertion of such commas in a melody, thus dividing it in smaller units. In this investigation two different methods are described that both tries to automatically place these commas at musically appropriate positions. The result is evaluated by comparing it with the preferred punctuation of a performer.
There are often several possibilities to place commas. For example, some performers may prefer to mark relatively long melodic units while others may prefer to make a finer division. To avoid these individual differences we chose to use the preferred punctuation of one performer as the reference.
The punctuation resembles the grouping analysis introduced by Lerdahl & Jackendoff (1983). Previous computational models for the detection of group boundaries has been presented by e.g. Tenney & Polansky (1980), Baker (1989) and Cambouropoulos (1997). However, the punctuation differs from a grouping analysis in two ways: (1) The grouping analysis is often assumed to model the cognitive grouping of events by the listener, i.e. performance cues can be used in the analysis, such as micropauses introduced by the performer. The automatic punctuation, on the other hand, tries to model the musicians choice of punctuation on the basis of the score only. (2) The punctuation model attempts to find the positions where a comma would be appropriate in the performance rather than find all possible places that emerges from a grouping analysis.
The main development of the punctuation rule has been by means of the analysis-by-synthesis method using the program Director Musices (Friberg, 1995b). The input is the coded music score using only pitch and duration information. Other marks such as articulation signs are disregarded. To identify appoggiaturas, the harmonic analysis is also included in the score description. As in our previous developments of performance rules (see e.g. Friberg, 1995b; Sundberg et al. 1991), Lars Frydén has served as the musical expert providing both musical judgement of synthesized performances and most of the musical ideas used for elaborating the rule. The rule has been developed and tested using a music material of about 60 melodic excerpts of various performers and styles, mainly from the classical repertoire.
The overall strategy of the rule is first to identify
potential, weighted locations of commas on the basis of the melodic
context. The maximum context length is five notes, two notes before
and two notes after the current note. This is realized by means
of 6 subrules which mark each note that precede a potential comma
with a weight number. If several subrules mark the same position,
the weights are added. In Figure 1 the five major melodic contexts
for potential comma locations are shown. They can divided into
two major types of contexts. (1) Contrast in (a) pitch
(melodic leaps, Fig. 1-2) and (b) duration. i. e. at note followed
by shorter note(s) (longest of five, Fig. 1-3; first short, Fig.
1-4; short between long, Fig. 1-5). (2) Melodic tension-release
(appoggiatura, Fig. 1-1).
Fig 1. Five main contexts generating allocations of potential commas (indicated) according to the punctuation rule. The contexts are (1) after appoggiatura; (2) in melodic leaps; (3) after the longest note in a series of five; (4) after a note followed by two or more shorter notes of equal duration; and (5) before a note surrounded by longer notes.
To make a further differentiation of potential locations, the weight value is in most cases proportional to contexts factors. Two major principles can be identified for the scaling of weights. (1) Contrast. The weight is (a) proportional to the duration ratio between the marked note and a certain context (longest of five, first short), (b) proportional to the leap size (leap), or (c) removed from comparatively short notes. (2) Tempo. Weights are reduced for notes of shorter durations, so that the number of marks is reduced in sequences of comparatively short notes (Leap).
There are also a set of 6 subrules that handles the
interaction of the potential comma locations. For example, weights
will be reduced when several of the duration contexts applies
to the same position or are removed on notes with relatively short
durations. A more complete description of the rule is given in
Friberg et al. (1997).
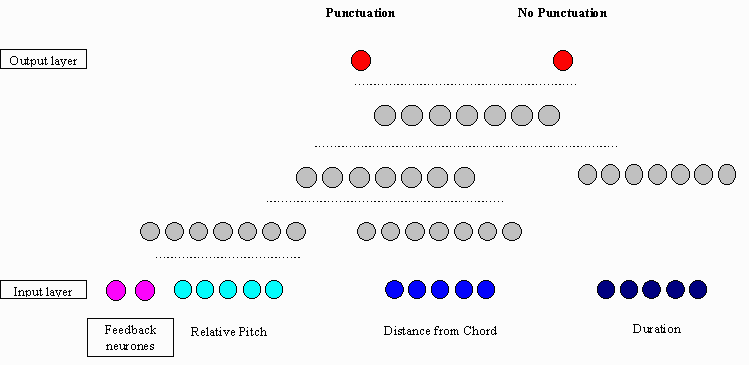
The architecture of artificial neural networks (ANNs) used in the present research was designed starting from the ANNs that were developed in previous research used to model musical performance (Bresin et al. 1992, 1993). A modification of the input and output data structure was necessary since the task for the ANNs in the present work is to indicate the notes that have to be punctuated in a score, according to the performer observations/marks. In previous models, on the other hand, the goal of the ANNs was to give duration and loudness deviations.
The basic idea of using ANNs instead of the rules described above was an attempt to make a better model of the interaction of the subrules and to see if a more accurate result could be obtained. Different ANN architectures are under development and different training, based on different subsets of the training melodies, will be performed. In the first training experiments a typical feed-forward structure was used: it placed a high number of punctuation marks in accordance with the performer indications but at the same time introduced a high number of musically unacceptable marks. For this reason we implemented the ANN shown in Figure 2. It is the version that was included in the evaluation below.
There are 15 input nodes using data extracted form the melody. They are divided into three groups of five node each, referring to a five notes context. The third note is the one to be judged to be punctuated. The information given in the input is each note's relative pitch distance to next note, its distance in semitones from the root of the prevailing chord, and its nominal duration in milliseconds. The difference from the first network was that two feed-back neurones (from the output layer to the input one) were added in order to give to the ANN information about the decision taken on the previous note (punctuated or not punctuated).
This architecture introduced less extra punctuation marks, in respect to the previous model, and most of them are musically acceptable. Furthermore this ANN was able to detect punctuation points matching the performer indications and not considered by the ANN without feed-back neurones. Results of this ANN are showed in tables 1 and 2.
Other experiments are under development: different
structures of the input data are being used, and training melodies
will be divided into subsets representing different composers
and music styles.
In order to assess the outcome of the punctuation a database of 52 melodic excerpts was assembled. Most of the melodies were taken from the classical repertoire, ranging from Baroque to contemporary music, but also including folk music and popular music. They were divided in two groups of 26 melodies each. The selection was made so that each group of examples from the same composer was divided equally among the two groups. The remaining melodies were randomly divided. The first group served as the optimization group and the second was used as the test group. All melodies were marked with the preferred punctuation by expert performer Lars Frydén.
Using the optimization group the weight parameters
of the punctuation rule were optimized. By means of an iterative
process, each weight parameter was systematically varied so as
to minimize the discrepancy between the rule generated punctuations
and those of the performer. The distance function that was minimized
was defined as
where NLF is the total number of marks by the performer, NSAME is the total number of marks by the rule that coincide with those of the performer, and NRULE is the total number of marks by the rule. This distance measure has the properties of both maximizing the NSAME and to force NRULE to be close to NLF.
The ANNs were trained using the well known "learning by error back-propagation" algorithm. Selected examples from the optimization group were used as the training data. Only 127 notes and 37 punctuations were selected (to train the rule all the melodies in the optimization group were used, including more the 1200 notes).
A typical example of punctuation marks is given in
Figure 3 where the commas by the performer, the rule and the ANN
are shown. This is an example where there is a general agreement
between the two systems and the performer. The resulting number
of commas for the optimization group for both the rule and the
ANN is shown in Table 1. The corresponding results for the test
group is shown in Table 2.

| RULE | ANN | ||||||
| Performer | |||||||
| bachbourrek | |||||||
| bachcmajfug | |||||||
| bachhkyrie | |||||||
| bäck | |||||||
| brahms | |||||||
| chpmazop67no4 | |||||||
| chpmazurka | |||||||
| clementine | |||||||
| ekor | |||||||
| handel | |||||||
| haydnkors | |||||||
| haydnquart | |||||||
| lucia | |||||||
| mendelson | |||||||
| mozamaj | |||||||
| mozebmaj | |||||||
| mozgmajquart | |||||||
| mozmenuet | |||||||
| ramel | |||||||
| sej | |||||||
| shubertheroic | |||||||
| shubertmilitary | |||||||
| shubertunfin | |||||||
| stravpetruska | |||||||
| varmeland | |||||||
| vide | |||||||
| total |
Table 2. Inserted commas by the performer, rule and ANN in the test group. See Table 1 for explanations.
| RULE | ANN | ||||||
| Performer | |||||||
| bachchaconne | |||||||
| bachgmfuga | |||||||
| bachsarabandek | |||||||
| berwald | |||||||
| bygnan | |||||||
| chpmazurk1 | |||||||
| chpwaltz | |||||||
| denforstagang | |||||||
| finnskog | |||||||
| haydnfmaj | |||||||
| haydnpuka | |||||||
| herdinna | |||||||
| mendelmidsum | |||||||
| mozalaturka | |||||||
| mozdminquart | |||||||
| mozgmaj | |||||||
| mozgminsymf | |||||||
| mozpisonat | |||||||
| roman | |||||||
| shubertavemaria | |||||||
| shubertichtraumte | |||||||
| shuberttrauer | |||||||
| sorgeliga | |||||||
| svinstad | |||||||
| varvindar | |||||||
| vila | |||||||
| total |
As seen in the tables, the optimization succeeded in making the total number of commas by the rule close to the total number of commas by the performer. As this is not directly controlled in the ANN, these numbers are somewhat higher in this case. In many cases the ANN gave an output very close to the behaviour of the rule system, indicating that the same general principles were used in both cases.
NSAME /NRULE and NSAME /NANN was used to estimate the efficiency of the punctuation. The relatively low values is not disappointing if we make a closer examination of the automatic procedures. It turns out that most marks are at a musically acceptable position. The following reasons have been identified regarding the difference of the automatic punctuation compared to the performers punctuation: (1) The performer was influenced by the text, especially in some well-known folk songs. One such case is "sorgeliga" in the test group where the performer chose to put a comma after each sentence instead of considering the small-scale musical structure. The rule and the ANN (with less marks) marked the musical structure in an correct way. (2) The performer sometimes made groups coinciding with the metrical structure. As the influence of meter is not taken into account, the automatic procedures has in general problems of matching such a case. However this often results in an "upbeat" phrasing instead, which in most cases is musically acceptable. One such example is "mozamaj" (Mozart A major sonata, K. 331) in which the performer put commas on the bar lines and both the rule and the ANN put commas before the note preceding the bar line. Both strategies were used by expert pianists in this piece, as demonstrated by Gabrielsson (1987). (3) Some of the places where the performer chose to omit a comma at a group boundary could not be predicted by the automatic procedures. This could be due to effects not taken into account here such as the harmonic progression or the phrase structure of the whole excerpt.
In summary, the rule and the ANN succeeded in making a musically acceptable punctuation. The modelling of the performers preferred punctuation could only be partly realized. Several aspects, such as the text and the meter was found to influence the performers choice. These aspects, as well as information about composer or music style, were not taken into account in the present models but will be included in future developments in this on-going project
We gratefully acknowledge the continuing support, co-operation and supply of ideas by Lars Frydén and Johan Sundberg. This work was supported by the Swedish National Council for Research in the Humanities and Social Sciences, by the Bank of Sweden Tercentenary Foundation and by EU TMR program (Training and Mobility of Researchers).