Speech Synthesis
We chose to make a simplistic synthesis in a limited number domain, as suggested in the practical assignment. In order to do this, a tcl-application was written to record the speech for synthesis. In pace with our experiences the application was equipped with various controls to manipulate the recordings. The controls were added to make the future synthesis sound as natural as possible. We realized quickly that the naturalness of the speech synthesis was threatened by all the variations which are present in speech, for example differences in pitch, timing, intonation and loudness. The silences between the two parts of speech that were concatenated can not be too long or too short. It sounds unnatural if digits in the beginning or in the middle of larger numbers are stressed. However, in the last digit (ex. 3 in 5063) stress can be an advantage.
To make use of our number reader we put it in a calculator application created especially for this purpose. The calculator was initially planned as an application with personalized speech synthesis and personalized speech recognition. However, due to time constraints we were not able to complete the calculator as we would have liked to.
Quick and Dirty Number Text To Speech Editor (QADNTTSE)
QADNTTSE is a tool to facilitate recording and fine-tuning of segments to use in a concatenation based number TTS. The Number-Text-To-Speech application (NTTS) we have made is using a minimal amount of pre-recorded numbers in order to make concatenative number synthesis of numbers between 1 - 999.999
The pre-recorded numbers used are:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 30 40 50 60 70 80 90 100 1000.
Since the assignment was not to make as good a synthesis as possible, but rather to make reflections on the topic, there are several aspects that this solution does not take into consideration, that does affect the quality of the synthesis.
A number like: 123.456 is built up of: 1 100 20 3 1000 4 100 50 6
The tool has been used to make several instances of a Swedish NTTS. One by Anna, one by Gunilla, and one by Preben. In addition, a Norwegian and a Chinese instance has been done.
The number system in Norwegian follows the same rules as in Swedish, except that an 'and' is required after 100 in Norwegian. It has simply been resolved by saying hundred-and in the recording of 100.
The Chinese number system is 10.000 based as opposed to normal western number systems that are 1000 based. After one thousand thousands, we change into one million. In Chinese they have a special word for 10.000 - 'wan', and one million becomes '100 wan', 10 million is '1000 wan', and a new unit 'i' is 'ten thousand ten thousands'. The NTTS we have implemented hence only works properly up to 9999 in Chinese.
The Chinese number system could have done without 11-19 as they are pronounced as 10-1 10-2 10-3 etc. but rather than changing the procedure that picks out the constituents from an input number, we have used the same procedure and recorded a few redundant utterances.
Listen to five different examples of "3658":
| Anna | Gunilla | Preben | Norwegian | Chinese |
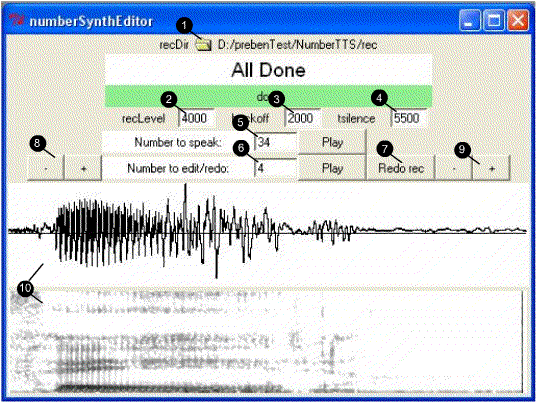
Usage:
[1] Location of the directory that will be used for recording and playback of sound files.
[2] Rec-level determines the threshold on what should be considered sound or silence
[3] Recording will go on in the background, and often it is necessary to have a short buffer (e.g. 500 ms) that is inserted in front of the moment rec-level is reached. Backoff is the number of samples inserted before the threshold is reached.
[4] Tsilence is the max number of samples of silence before the sound detection procedure considers the recording to be done.
[5] This is where the number to be spoken by the concatenative synthesis is to be entered. When all the numbers are recorded this is the only entry needed, and a more compact application for playing only can be used.
[6] In this entry a single number file can be entered, and viewed in 10.
When the cursor is in this entry, keyboard shortcuts 'Return' will play the file and 'Control-p' will play the number in [5]
This is typically used to listen to the file edited in [6] in combination with something else. In the screenshot example the number '4' is edited, and examined together with the number '30' to create the concatenation 34.
This is also where the initial recording is done (in this version of the program).
[7] If the recording is not considered good it can be redone by pressing the 'redo rec' button or by pressing 'control-r'.
NB Beware! Any old recording of the number in entry [6] is then overwritten.
[8] The + and - buttons on each side of the wavefile are used to increase or decrease the size of the recording. The buttons on the left side adds or removes a small segment in front of the recording
[9] The buttons on the right side adds or removes a small segment at the end of the recording.
[10] waveform and spectrogram of the recording edited in [6]
The Exe files for windows can be downloaded here
numberSynth.exe
numberSynthEditor.exe
Example recordings (3 Swedish one Norwegian and one Chinese)
The source files can be downloaded here.
nttsSource.zip (This requires Tcl/Tk to be installed on your system but should then work on Linux/Unix/Windows/Mac)
The program is built in Tcl/Tk and uses the 'snack' package developed at CTT http://www.speech.kth.se/snack/
Post processing
As stated in the introduction, the timing is of great importance. If the recorded speech are spoken with different speed, the combined result may sound a bit jerky. Moreover, the duration of each segment seem to vary with the complexity/length of the utterance, and the position of the segment. The numbers are spoken with a "rythm", which means that a bisyllable word (i.e. "fyra") is uttered faster to match a monosyllabic word (i.e. "två"), as in "284" ("tvåhundraåttifyra"). To adjust the output to these constraints, we were thinking of a normalisation of the segments, based on the average durations of the recordings, and then apply these according to some quotes for duration of each segment. However, in order to get some idea of the relation of these durations, a rather time consuming analysis was needed.
Instead we focused on a simpler feature. Since the duration of a segment is prolonged when stressed, and the final digit is most likely to be emphasised, we experimented with time stretching where all segments except the last was played faster. We also tried to instead lengthen the final segment rather than shortening the others, but the quality of the speech was more degraded that way.
Please listen to the examples and judge yourself!
Original |
0.85 |
0.75 |
|---|---|---|
| 23 | 23 | 23 |
| 341 | 341 | 341 |
| 5029 | 5029 | 5029 |
Home