|
Gabriel Skantze
Professor in Speech Technology
|

|
Department of Speech Music and Hearing
School of Computer Science and Communication
KTH Royal Institute of Technology
Young Academy of Sweden |
Situated Human-Robot Interaction
Spoken dialog technology has for a long time neglected the physical space in which the interaction takes place. Applications such as ticket booking over the telephone assume that the system interacts with a single user, and that the system and user are not physically co-located. In contrast to this, situated interaction takes place in a physical space, where there may be several users interacting with the system (and each other) at the same time, and the user and system may refer to objects in the surroundings.
The following video shows a dialogue system that was exhibited at the Swedish National Museum of Science and Technology in 2014. Two visitors are playing a game together with the robot head Furhat. The video is best viewed in 1080p and full screen.
IrisTK: a toolkit for situated interaction
Face-to-face multi-party interaction involves a large amount of real-time events that need to be orchestrated in order to handle phenomena such as overlaps, interruptions, coordination of headpose and gaze in turn-taking, etc. Also, the knowledge to develop and put together all necessary modules is of a very interdisciplinary nature. To facilitiate the development of such systems, we have developed a dialog system toolkit called IrisTK, which is released as open source.
We have currently integrated a wide range of modules for the toolkit that handle visual input, speech recognition and speech synthesis, including Microsoft Kinect, Frauenhofer SHORE, Nuance ASR and Cereproc TTS.
To make the authoring of the dialogue behaviour more efficient and simpler, we have defined an XML-based authoring language for dialog flow control, called IrisFlow, which can be regarded as a variant of Harel statecharts - a visual formalism for defining complex, reactive, event-driven systems. IrisFlow is similar to SCXML, but adds functionality such as recursive state calls, which allows for a much more compact representation. IrisFlow can be used not only to control the high-level dialogue behaviour, but also to orchestrate low-level events such as facial gestures, eye blinks, etc.
We have used IrisTK to implement a face-to-face multiparty dialogue system with the Furhat head (see below), which was exibited at the London Science Musem in 2011, as part of the Robotville Festival (showcasing some of the most advanced robots currently being developed in Europe). During the four days of the exhibition, Furhat interacted with thousands of visitors of all ages. The system was also exhibited at Tällberg Forum (see video on the right). We also demonstrated the system at the 14th ACM International Conference on Multimodal Interaction (ICMI) 2012 and received the Outstanding Demo Award.
Skantze, G., & Al Moubayed, S. (2012). IrisTK: a statechart-based toolkit for multi-party face-to-face interaction. In Proceedings of ICMI. Santa Monica, CA. Skantze, G., Hjalmarsson, A., & Oertel, C. (2014). Turn-taking, Feedback and Joint Attention in Situated Human-Robot Interaction. Speech Communication, 65, 50-66.Furhat: a back-projected robot head

Most studies on more sophisticated multi-party interaction have utilized an embodied conversational agent presented on a flat screen. This may be problematic, however, due to the phenomenon known as the Mona Lisa effect: Since the agent is not spatially co-present with the user, it is impossible to establish exclusive mutual gaze with one of the observers either all observers will perceive the agent as looking at them, or no one will. While mechanical robot heads are indeed spatially and physically co-present with the user, they are expensive to build, inflexible and potentially noisy. The robot head Furhat, developed at KTH, can be regarded as a middle-ground between a mechanical robot head and animated agents. Using a micro projector, the facial animation is projected on a three-dimensional mask that is a 3D printout of the same head model used in the animation software. The head is then mounted on a neck (a pan-tilt unit), which allows the use of both headpose and gaze to direct attention. The neck and lip-synchronized speech has been integrated into the IrisTK framework, allowing us to easily do experiments and build demonstrators.
Al Moubayed, S., Skantze, G., & Beskow, J. (2013). The Furhat Back-Projected Humanoid Head - Lip reading, Gaze and Multiparty Interaction. International Journal of Humanoid Robotics, 10(1).Gaze in situated interaction
Compared to other primates, the color of the sclera ("the white of the eye") in human beings is clearly distinct from the iris, due to the lack of pigment. This contrast in human eyes is useful for determining the direction of other people's gaze and thereby their focus of attention. It has been hypothesized that this unique feature of humans eyes has evolved due to the fact that humans to a larger extent are dependent on "reading" other people's minds and follow their gaze while communicating or solving joint tasks.
Using Furhat and IrisTK as research tools, we have investigated how the 3D design of Furhat affects the interaction in a multi-party dialogue setting. We have also investigated how factors such as dynamic eye-lids, vergence and viewing angle affect humans perception of the target of Furhats gaze.
Al Moubayed, S., & Skantze, G. (2012). Perception of Gaze Direction for Situated Interaction. In Proc. of the 4th Workshop on Eye Gaze in Intelligent Human Machine Interaction.. Santa Monica, CA, USA. Al Moubayed, S., & Skantze, G. (2011). Turn-taking Control Using Gaze in Multiparty Human-Computer Dialogue: Effects of 2D and 3D Displays. In Proceedings of AVSP. Florence, Italy.Incremental, real-time dialogue processing
Already when the first words are being uttered by the conversation partner, we start to make sense of them. This incremental processing allows us to give feedback while the interlocutor is speaking, in the form of head nods and short utterances such as mhm. Such feedback helps the speaker to understand whether the listener is following, and whether she understands and agrees to what is being said. Incremental processing also allows us to prepare our reactions and be ready to respond without any noticeable gaps between the turns of the conversation.
Replicating the real-time processing of humans requires a fundamental rethinking of how to process spoken language in dialogue systems. Typically, a pipeline of modules such as speech recognition, speech understanding, action selection, speech generation, and speech synthesis is used to process the users utterance and to produce a system response, where each module processes a complete utterance before passing it on to the next. Such systems typically wait for the user to finish speaking before doing any processing of the spoken input. A simple silence threshold is often used to decide when the utterance is finished, after which the processing starts. To achieve real-time processing, all modules should instead process the input in a concurrent fashion, passing on incremental units of information, which represent tentative hypotheses of what is being said and what the system should do next.
If you are interested, please take a look at my 45 minute lecture on Incremental Dialogue Processing. Or read the releated research papers:
Schlangen, D., & Skantze, G. (2011). A General, Abstract Model of Incremental Dialogue Processing. Dialogue & Discourse, 2(1), 83-111. Skantze, G., & Schlangen, D. (2009). Incremental dialogue processing in a micro-domain. In Proceedings of EACL-09. Athens, Greece.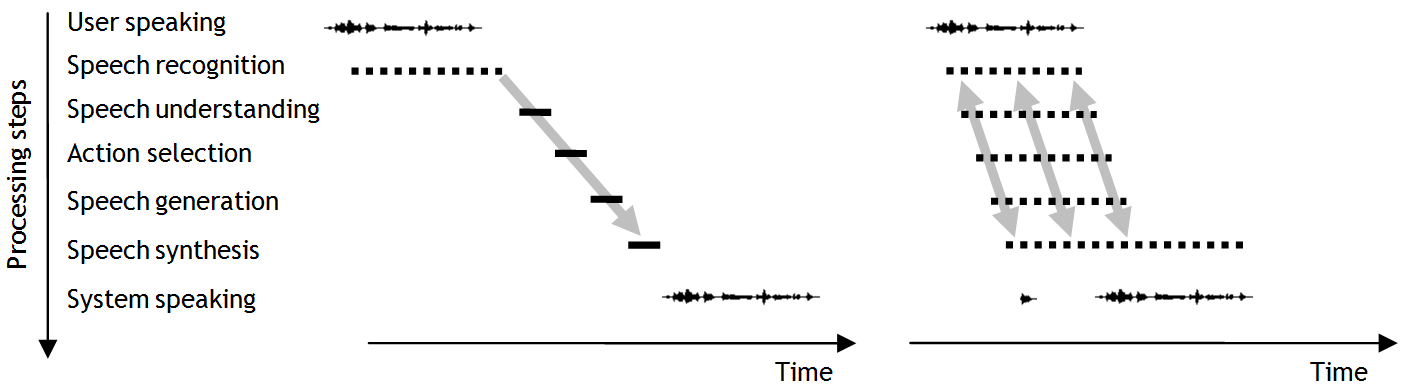
Incremental speech generation
When starting to speak, dialogue participants typically do not have a complete plan of how to say something or even what to say. If the speaker would not start to speak before the complete utterance was formulated and the articulatory plan was complete, this would result in long response delays. Since this is not the case, humans apparently start to speak while simultaneously conceptualising and formulating the utterance.
Using the Jindigo framework, developed by me, we have implemented a model of incremental speech generation for practical conversational systems. The model allows the system to incrementally interpret spoken input, while simultaneously planning, realising and self-monitoring the system response. If these processes are time consuming and would result in a response delay, the system can automatically produce hesitations to yield the floor. While speaking, the system also utilizes hidden and overt self-corrections to accommodate revisions in the system.
At SIGdial 2010, we received the Best Paper Award for our work on incremental speech generation.
Skantze, G., & Hjalmarsson, A. (2012). Towards Incremental Speech Generation in Conversational Systems. Computer Speech & Language, 27(1), 243-262.Modelling feedback in spoken dialogue
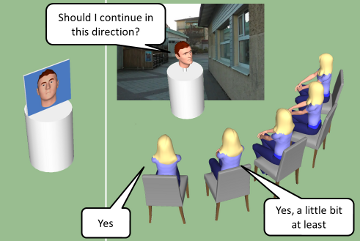
Map Task is a common experimental paradigm for studying human-human dialogue, where one subject (the information giver) is given the task of describing a route on a map to another subject (the information follower). We have developed a dialogue system that can do the Map Task with a user, which serves as a test-bed for doing studies on feedback behaviour. Implementing a Map Task dialogue system with full speech understanding would indeed be a challenging task, given the state-of-the-art in automatic recognition of conversational speech. In order to make the task feasible, we have implemented a trick: the user is presented with a map on a screen and instructed to move the mouse cursor along the route as it is being described. The user is told that this is for logging purposes, but the real reason for this is that the system tracks the mouse position and thus knows what the user is currently talking about. It is thereby possible to produce a coherent system behaviour without any speech recognition at all, only basic speech detection.
While there have been many studies which investigate the cues that may help humans determine where it is appropriate to give feedback (such as prosody and syntax), these are typically done on human-human data. We have used the Map Task system to collect data on feedback-inviting cues in human-computer dialogue and trained a model based on prosody and dialogue context, using Support Vector Machines. This procedure will allow us to test the model online in an interactive human-computer dialogue setting.
Meena, R., Skantze, G., & Gustafson, J. (2014). Data-driven Models for timing feedback responses in a Map Task dialogue system. Computer Speech and Language, 28(4), 903-922. Skantze, G. (2012). A Testbed for Examining the Timing of Feedback using a Map Task. In Proceedings of the Interdisciplinary Workshop on Feedback Behaviors in Dialog. Portland, OR.