The synthetic face from a hearing impaired view (Fonetik98)
The
synthetic face from a hearing impaired view
Eva Agelfors , Jonas
Beskow, Martin Dahlquist, Björn Granström, Magnus
Lundeberg,
Karl-Erik
Spens & Tobias Öhman,
Department
of Speech, Music and Hearing, KTH,
Stockholm, Sweden.
Email: teleface@speech.kth.se
Abstract
In the
Teleface Project the possibilities for a visual telephone communication aid for hearing impaired persons are being
evaluated. Multimodal speech
intelligibility experiments showed a marked intelligibility advantage for
the addition of the face information, both for natural and synthetic faces.
This is valid for hearing impaired persons as well as for normal hearing
persons in a noisy environment. In this paper we present results from two
series of tests with hearing impaired subjects.
Introduction
The Teleface project at KTH focuses on the usage
of multimodal speech technology for hearing impaired persons. The aim of
the first phase of the project is to evaluate the increased intelligibility
hearing impaired persons experience from an auditory signal when it is
complemented by a synthesised face. A demonstrator of a system for telephony
with a synthetic face that articulates in synchrony with a natural voice
will be implemented in phase two of the project.
Audio-Visual Speech Synthesis and
Analysis
The project's different stages involve different
kinds of processing of acoustic and visual speech data. In the intelligibility
study, we utilize a rule-based audio-visual text-to-speech-synthesis framework
(Beskow, 1995) to generate synthetic acoustic, as well as visual, speech
stimuli. This parametrically controlled visual speech synthesis will also
form the basis for the intended telephone conversation aid in phase two of the project.
Automatic extraction of facial parameters from the
acoustic signal requires extensive analysis of the relationship between
the facial parameters and the acoustics. To this end, we have built a framework
for automatic measurements of visible speech movements (Öhman, 1998).
A database of video sequences of a male speaker has been recorded. Parts
of the speakers face have been marked with a blue color to facilitate image
analysis of lips and other parts of the face that are important for speechreading.
The parameters from the optical measurements will be statistically analyzed
together with the acoustic signal, providing knowledge about the relationship
between the visual and acoustic modes of speech. The optical measurements
will also be used to improve naturalness of the visual speech synthesis.
Intelligibility tests
Preliminary test with normal hearing subjects
A preliminary test was performed with normal hearing subjects. The subjects
were 18 fourth-year-students in engineering at KTH. The audio signal was
degraded by adding white noise. The results for the VCV corpus show that
adding a synthetic face to a natural male voice increases correct responses
from 63% to 70%. Corresponding result for adding a natural face is 76%
(Beskow et al., 1997).
First test with hearing impaired subjects
Subjects and method
The first round of the test series involved 12 subjects with a severe
to profound hearing loss for the better ear with a mean of 88.4 dB pure
tone average hearing level (HL), (range, 62-103 dB) at the frequencies
0.5, 1 and 2 kHz. 11 subjects are experienced hearing-aid users (HA) and
one subject uses a cochlea implant (CI). The subjects were between 23 and
76 years old with a mean age of 58.2 years. The speech was presented at
about 70 dB SPL and each subject was allowed to adjust their hearing aid
to their most comfortable listening level during a training session (2x5
sentences of the natural and the synthetic faces respectively).
The test material consisted of VCV-syllables, "everyday sentences" and
a questionnaire.
The VCV-syllables consisted of seventeen consonants presented in /aCa,
iCi, uCu/ context. Three test lists (3 x 17 stim./list) were presented
in different conditions for the subjects
(2 audio-visual and 1 audio alone). Subjects were asked to respond
with the consonant. Responses for the VCV corpus were force-choice and
made with a graphical interface on a computer screen. The sentences were
unrelated "everyday sentences" developed at TMH by Öhngren based on
MacLeod and Summerfield (1990). Each list contained 15 sentences (45 keywords
i.e. three keywords/sentence). Six test lists were presented, two test
lists of each condition (2 audiovisual and 1 audio alone). The number of
correctly repeated keywords were counted and expressed as the percent keywords
correct. Responses for the sentences were given verbally.
The visual database is identical to the database that we use for the
visual measurements, but without colors and markers in the face. The speaker
is a Swedish male from Stockholm. During recording of the database, the
speech rate was kept constant by prompting the speaker with text-to-speech
synthesis set to normal speech.
Results
The results for the VCV corpus showed a significant gain in intelligibility
when adding a face to a natural voice. The result for the natural voice
only was 31% correct responses. When adding a synthetic face the result
improved to 54% correct, with a natural face it was 57%. Results for the
sentence corpus are presented in Table 1. The benefit of adding a synthetic
face varied a lot between different subjects. This is probably due to a
combination of the kind of hearing loss and the ability to speechread.
Some subjects had a result with the synthetic face very close to the result
with the natural face. On the other hand one subject with a profound hearing
loss seemed to get very little information from the synthetic face although
the same subject got 82 % keywords correct with the natural face (Figure 1).
Second test with hearing impaired subjects
Subjects and method
The second group consisted of 12 adult subjects with a mild to profound
hearing loss (11 HA-users, 1 CI-user) and 3 subjects who participated in
the first round and now were retested. The subjects were between 37-82
years old (mean 59,1) with a hearing loss of 83.2 dB HL (range 32-113 dB).
The method and corpus differed from that of the first round in the following
ways: a) Only the sentence corpus was used. The sentence lists were scrambled
compared to round one. b) The audio signal was filtered to telephone bandwidth
in order to get the test conditions closer to those of the intended Teleface-application.
c) Visual distraction was introduced as one condition of the test without
the subjects knowledge. This was done by displaying the synthetic face
with articulatory movements generated by a simple phoneme recognizer not
trained on our corpus. d) A visual only condition was introduced. This
had not previously been tried with the synthetic face.
Table 1. Results for the sentence corpus (% keywords correct). Last
row shows result from the second round with the articulation generated
by using a phoneme recognizer.
|
Natural voice
|
Synthetic face
|
Synthetic face and natural voice
|
Natural face
|
Natural face and
natural voice
|
|
First round
|
41%
|
Not tested
|
65%
|
Not tested
|
82%
|
|
Second round
|
57%
|
3%
|
66%
|
16%
|
83%
|
|
w. recognizer
|
-
|
-
|
51%
|
-
|
-
|
Results
We couldn't see any significant difference between the results from
the first and second round for the retested subjects. The characteristics
of their hearing loss, implies that a telephone bandwidth filtering of
the speech signal doesn't make much difference in intelligibility. Therefore
it is possible to compare the results from the first and the second round.
However, comparing results between the two groups should be done carefully
since the subjects' individual differences in hearing loss are large.
Results from the second round are presented in Table 1. As in the first
round the differences in the results between the individual subjects are
large. The visual distraction generated with the phoneme recognizer was
obvious for the subjects with a profound hearing loss and they got a lower
score in that test condition. For subjects with a mild hearing loss the
distracted visual stimuli didn't affect their results very much, probably
because they relied on their hearing.
The answers from the questionnaire showed that the subjective opinions
about the synthetic face matches the objective results for the subjects
with a profound to severe hearing loss (Figure 1). The lesser the degree
of hearing loss, the larger the variation between the subjective and objective
result. The retested subjects rated the benefit of the synthetic face a
little lower in the second round than in the first round. The reason for
this is probably the sometimes incorrect articulatory movements that we
introduced as one condition of the tests without the subjects' knowledge.
Every subject was presented two lists of sentences per audio-visual combination.
We found a significant learning effect between the first and the second
list with the synthetic face but not with the natural face. The average
over all subjects for the first list was 62 % and for the second list 71
% keywords correct.
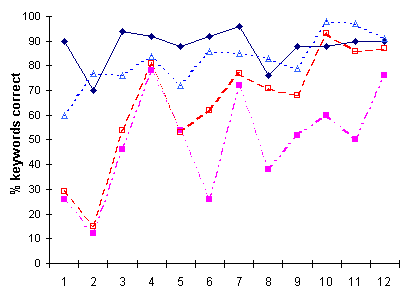
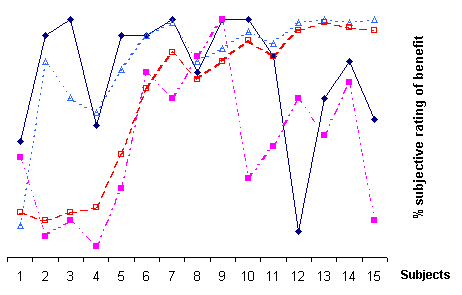

Figure 1. The subjective ratings of benefit (maximum
100 %) and objective results of speechreading from the first round (left)
and the second round (right). The subjects are presented in order of increasing
performance on the audio only condition of the test.
Conclusions and future work
The highest absolute benefit from speechreading a
synthetic face is obtained by the subjects with such a hearing loss that
they reach between 40 and 80 % keywords correct in the audio only condition
of our experiment. These are the ones that would have the best use of a
visual hearing aid like the intended Teleface-application. Subjects with
a lower score often get a good gain from adding a synthetic face to the
natural voice, but although the gain is high they will probably not benefit
enough in a telephone situation, since their starting point is too low
(Figure 2). Subjects with a higher score than approximately 80 % keywords
correct seem to rely on their hearing and therefore they do not gain very
much from adding a face, synthetic or natural, in our experiment. We have
showed earlier (Beskow et al., 1997) that normal hearing persons benefit
from a synthetic face when audio is being degraded by adding white noise.
This most probably also applies to persons with a hearing loss.
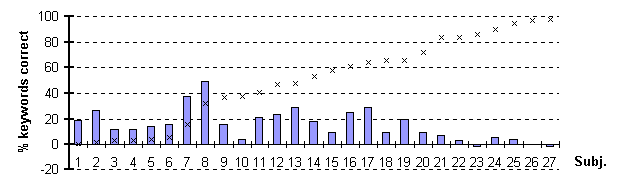
Figure 2. The bars show the contribution of a synthetic
face when added to a natural voice in relation to the performance on the
audio only condition (x). The subjects are presented in order of increasing
performance on the audio only condition of the test.
The result for the first phase of the project presupposes
a perfect mapping from acoustics to facial gestures. Preliminary studies
in the second round of phase one, with a simple phoneme recognizer not
trained on our database show that displaying not so good articulation movements
decreases the intelligibility. The current research in this area is now
focused on how to train a speech recognizer for the special needs of the
intended Teleface-application.
Acknowledgements
The work is funded by KFB,
the Swedish Transport and Communications Research Board, and CTT,
the Centre for Speech Technology, KTH.
References
Beskow, J. (1995). Rule-based Visual Speech Synthesis.
Proceedings of Eurospeech '95, Madrid, Spain. [postscript][gzipped
postscript]
Beskow, J.,Dahlquist, M., Granström, B., Lundeberg, M., Spens, K-E & Öhman, T. (1997). The Teleface project - Multimodal
Speech Communication for the Hearing Impaired.
Proceedings of Eurospeech '97, Rhodos, Greece. [postscript][gzipped postscript]
MacLeod, A. & Summerfield, Q. (1990), A procedure
for measuring auditory and audiovisual speech-reception thresholds for
sentences in noise. Rationale, evaluation and recommendations for use.
British Journal of Audiology, 24:29-43.
Öhman, T. (1998). An audio-visual database in
Swedish for bimodal speech processing. TMH-QPSR , KTH, 1/1998.
{kind=link}